




I. Introduction▲
Objet de cet article▲
L'un des objectifs de l'ETL est la transformation des données (Extract Transform and Load). Pour certains, il n'y a transformation que lorsque l'on change la nature de l'information (changement de type, création d'une colonne dérivée, agrégation, etc.) et ce n'est pas complètement faux. Cependant, ce processus de transformation encapsule également celui de préparation à cette transformation et de contrôle de cette dernière. Plusieurs composants du Data Flow permettent cela comme le Multicast et le Sort. Justement, cette opération de tri sera l'objet de ce tutoriel. Nous verrons les différentes façons de trier les données et l'utilité que cela peut avoir dans un lot SSIS.
Prérequis▲
Afin d'avoir une pleine compréhension de cet article, il suffit de connaître les bases de l'outil SSIS à savoir :
- les principaux composants du Control Flow ;
- les principaux composants du Data Flow.
À ce propos, vous trouverez une description des principes de SSIS avec le tutoriel Présentation de SQL Server Integration Services.
II. Le composant Sort▲
Le composant qui nous apparaît naturellement lorsque l'on souhaite effectuer un tri de nos données sur SSIS est bien évidemment le Sort. C'est d'ailleurs l'un des composants les plus couramment utilisés.
Spécificités▲
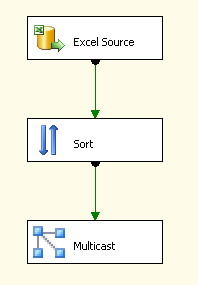
Dans l'exemple ci-dessous, il est placé entre la source de données (un fichier Excel) et un composant Multicast. Comme pour la majorité des composants du Data Flow, Sort dispose d'une entrée et d'une sortie. Sur son entrée, Sort va prendre en compte les lots de données issues de la sortie de l'objet Excel Source. Les données vont être triées selon les colonnes que nous aurons spécifiées et le résultat sera envoyé sur la sortie (qui correspond à l'entrée du Multicast).
Jusque là rien d'extraordinaire donc, mais nous allons maintenant nous intéresser aux spécificités du Sort par rapport à d'autres méthodes de tris. Tout d'abord, en tant que composant SSIS, il faut prendre en compte le comportement de Sort, inhérent à chaque objet. Comme décrit dans un tutoriel précédent (voir Comportement des composants SSIS), Sort est ce que l'on appelle un objet bloquant, c'est-à-dire qu'il doit disposer de toutes les lignes sur son entrée et avoir effectué le processus de tri sur toutes ces lignes avant de les envoyer sur sa sortie. Pour une opération comme le tri, on comprend aisément cette nécessité de disposer de l'ensemble de l'information avant de pouvoir passer à la prochaine étape. Cette spécificité fait de Sort un composant gourmand en ressources lorsque le nombre de lignes et de colonnes à traiter est important.
Il contribuera entre autres à la synchronisation de notre lot (on entend par synchronisation le fait que le composant en amont aura besoin d'avoir traité toutes les lignes avant de les mettre à disposition du composant en aval) ce qui aura pour effet d'accroître le temps d'exécution global du package.
Utilisation▲
L'image ci-dessous montre les propriétés principales du Sort :
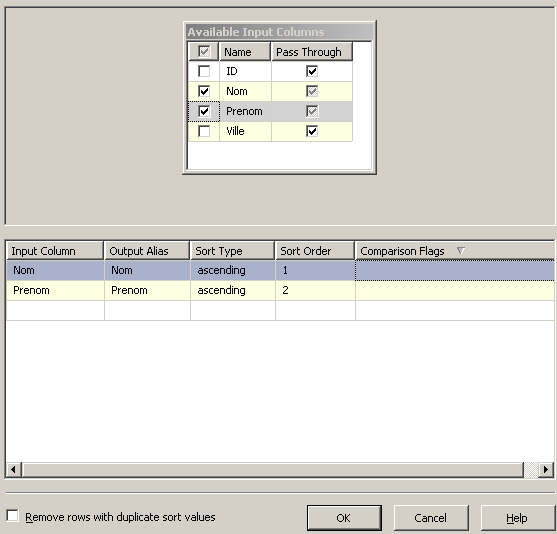
- Pass Through : permet de déterminer si la colonne sera à prendre en compte dans le flux de données ;
- Sort Type : tri croissant ou décroissant ;
- Sort Order : définit les priorités de tri pour les colonnes ;
- Comparaison Flag : définit des options sur le tri : Ignore Case, Ignore Symbols, etc.) : attention, ces options influent sur le calcul des doublons ;
- Remove rows with duplicate sort values : supprime les lignes en double : attention, les doublons seront calculés sur les colonnes participant au tri (ici Nom et Prenom).
La suppression des doublons du data set▲
Pour terminer sur le composant Sort, nous nous intéresserons à l'une de ces options assez régulièrement utilisées : la suppression des doublons dans notre data set. L'une des premières choses à retenir c'est que le composant Sort va déterminer les doublons en fonction de la clé de tri. Si nous reprenons notre exemple, ils seront déterminés sur les colonnes Nom et Prenom. Ainsi les tuples {6261, Austine, Alexandre, Caen}, {43701, Austine, Alexandre, Rouen} et {47781, Austine, Alexandre, Lyon } seront traités comme des doublons.
Lorsque doublon il y a, c'est la dernière occurrence rencontrée qui sera conservée dans le data set (toujours dans notre exemple, c'est la ligne avec l'ID 47781 qui persistera pour la clé de tri {47781, Austine, Alexandre, Lyon }). Dans le cas où un Comparaison Flags a été spécifié, il en sera tenu compte pour la détermination de doublons. Ainsi, pour un Comparaison Flags à « Ignore Case », les tuples suivants seront des doublons :
- {6261, Austine, Alexandre, Caen }
- {43701, austine, Alexandre, Rouen }
- {47781, austine, alexandre, Lyon }
Recommandation : plutôt que d'utiliser un composant Sort dans le seul but de supprimer des doublons, il serait préférable, dans la mesure du possible, d'ajouter une clause « distinct » dans la requête d'extraction des données.
III. La clause Order By▲
Contrairement au composant Sort qui trie les données se trouvant dans le data flow, une clause Order By permettra quant à elle de réaliser l'opération de tri lors du l'extraction des données à partir de la source. Cette clause est applicable aux données issues d'un système de gestion de base de données (SGBD), mais également à celles provenant de fichiers Excel, le tout via une instruction SQL. À ce moment-là, c'est le moteur SQL qui gérera l'opération de tri. On évitera ainsi de passer par de la copie de buffer via le moteur SSIS comme l'oblige le Sort.
Bien entendu, cette solution est à retenir dans le cas où le serveur hébergeant le moteur de base de données est suffisamment robuste pour réaliser ce genre d'opération. Des tests sont donc à prévoir pour déterminer s'il vaut mieux utiliser un ordre SQL ou un composant Sort.
IV. Cas particulier : une source de données déjà triée▲
Qu'en est-il des données déjà ordonnées dans la source ? Imaginons un fichier Excel contenant une liste de client pour le marketing déjà triée sur l'identifiant. Cet ordonnancement, nous voulons le retrouver dans le lot SSIS de manière à pouvoir fusionner les colonnes de notre fichier marketing avec des informations « clients comptables » issues d'un autre fichier Excel via l'opérateur Merge Join (nous avons volontairement choisi le composant Merge Join, car ce dernier n'accepte que des data sets triés sur ses entrées).
Il n'est plus nécessaire alors d'utiliser un composant Sort ou une clause Order dans la commande SQL. Cependant, nous devons spécifier au moteur SSIS que nos données sont bel et bien triées. Si nous ne réalisons pas cette opération, nous aurons le droit à ce message d'erreur. Dans le cas d'un Merge Join voici ce qu'il se passe :
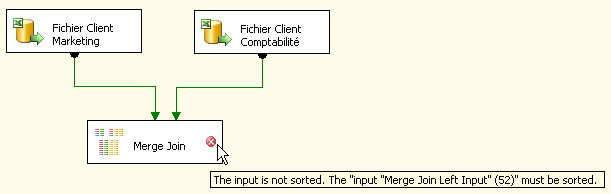
Pour y remédier, il faudra réaliser les opérations suivantes. Notre objectif étant de fusionner les fichiers contenant les données de marketing et de comptabilité, ces derniers ont été préalablement triés sur la colonne ID. Dans les propriétés avancées des composants Excel Source puis dans l'onglet Input et Output Properties, nous retrouvons l'arborescence suivante :
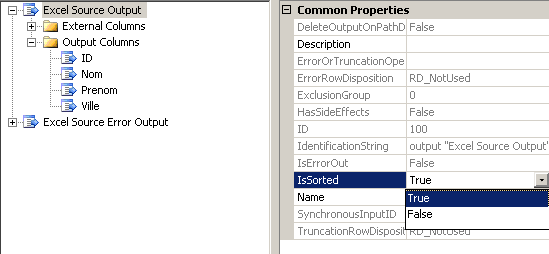
Nous trouvons ci-dessus la sortie de notre composant (dont le nom est Excel Source Output : ce dernier est d'ailleurs paramétrable grâce à la propriété Name que l'on distingue en dessous de IsSorted). La première chose à faire et de spécifier que le buffer correspondant à cette sorte est trié. Pour cela on passe la propriété IsSorted à True.
Une fois cette opération terminée, il faut préciser l'ordonnancement des colonnes : on constitue alors notre clé de tri. Dans notre fichier Excel, les données sont triées par ID. Comme le montre le schéma ci-dessous, il faut passer la propriété SortKeyPosition de la colonne ID à 1 :
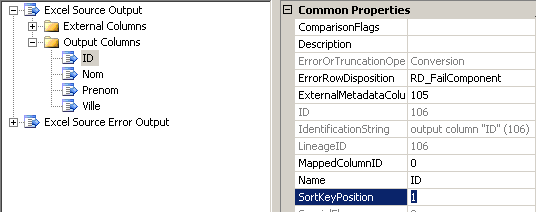
Par défaut, SortKeyPorition vaut 0, ce qui signifie que la colonne ne participe pas à la constitution de la clé de tri. Si nous avions trié nos données par ID puis par Nom, la propriété SortKeyPosition vaudrait alors 1 pour ID et 2 pour Nom. Inversement, si le tri avait été réalisé par Nom puis par ID, alors la propriété SortKeyPosition vaudrait 1 pour la colonne Nom et 2 pour ID et ainsi de suite. On notera également la présence de la propriété ComparaisonFlags que nous avions découverte avec le composant Sort.
Bien entendu, il faudra répéter cette opération autant de fois qu'il y a de sources de données. Ces propriétés sont accessibles sur tous les composants source natifs de SSIS.
V. Conclusion et remerciements▲
Conclusion▲
L'étape de tri des données est presque incontournable dans la mise en place d'un processus ETL et elle est présente de nombreuses fois en différents endroits de votre projet. Elle est relativement simple à mettre en place et c'est pour cela qu'elle est trop souvent négligée, car on n'imagine pas alors l'impact qu'elle peut avoir sur les performances lorsqu'elle est mal implémentée.
Remerciements▲
Je souhaitais remercier Fleur-Anne pour la relecture et les corrections apportées à ce document.